AI adoption • Cost model • Infrastructure
AI Isn't $40 SaaS, It's Infrastructure — That's Why They're Building Power Stations
Executive summary: As AI moves from experimentation into everyday work, costs stop behaving like per-seat software. When friction is removed, usage accelerates because more work gets done. The response isn't to cap usage, but to provision AI deliberately — preserving premium capability for high-value work, while supplying the bulk of demand efficiently as tasks are delegated to AI systems that iteratively try, validate, and retry solutions without human intervention.
Victoria just announced what could be Australia's largest data centre — 720 MW of capacity in the Latrobe Valley, built on a former industrial site in the heart of a renewable energy zone.
That's not speculation about AI's future. It's infrastructure being built to handle what's already happening.
Most organisations still treat AI as a $40-per-user SaaS line item. That assumption holds right up until AI moves from experimentation into everyday work.
It's an understandable assumption. Most AI tools are sold like SaaS: per-seat pricing, a tidy monthly number, and the comforting idea that costs are naturally capped.
This is a familiar lesson from cloud adoption. When infrastructure teams made it trivial to spin up EC2 instances, teams didn't become more cautious — they became faster. New services appeared, experiments hardened into products, and delivery velocity increased dramatically. Cloud didn't reduce spending; it removed friction — and that frictionless environment enabled teams to build at a pace that simply wasn't possible before.
AI follows the same trajectory. Once teams move beyond experimentation and integrate AI into real work, usage scales naturally — and the SaaS pricing model stops matching reality.
That isn't a failure of pricing. Usage-based models work exactly as intended when a tool becomes indispensable. As teams become more fluent, they extract more value — and consume more tokens in the process. The real mismatch is organisational: most companies are still budgeting for trial usage, while planning — often implicitly — for full adoption.
What day-to-day AI usage actually looks like
Early usage is cautious: small prompts, limited context, occasional assistance.
As teams become comfortable, usage changes in predictable ways. AI stops being a helper and starts taking on real work:
- Refactoring systems that span multiple services
- Reasoning across real codebases, not isolated files
- Inspecting CI/CD failures, identifying pipeline errors, correcting configuration, and triggering rebuilds
- Producing first-pass implementations, tests, and documentation
None of this is exotic. It's simply what happens when routine tasks are delegated to something that's always available.
For non-technical leaders, this is the key point: the screenshot below is not showing anything unusual or out of control. It's a normal slice of a workday where multiple people are using AI in parallel, across different tools and tasks. Each line item is small on its own — but together they represent real work being completed faster than would otherwise be possible.
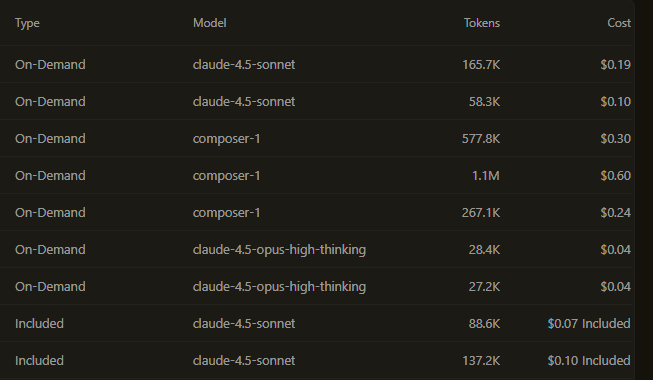
How AI usage aggregates into real spend
Most AI interactions look cheap in isolation — $0.10 here, $0.30 there. Individually, they barely register.
But a normal workday can easily mean 10 to 100 AI interactions per person. Some are trivial. Some are substantial. All of them count.
Once teams are comfortable delegating real work, daily spend in the $50–$100 per person range is entirely normal — even without inefficiency or misuse.
Annualised, that's no longer "tooling spend". It starts to resemble the cost of one or two full-time roles. That comparison often makes people uncomfortable, but it's the correct one.
Early cloud spend followed the same pattern. For a long time, organisations carried two cost bases in parallel: legacy infrastructure that still had to run, and new cloud environments that teams were learning, experimenting with, and gradually trusting.
During that phase, spend looked inefficient on paper. Servers were still being maintained on-premises. Licences were still being renewed. At the same time, engineers were spinning up new instances, building new services, and discovering what was possible when infrastructure friction disappeared.
That dual spend wasn't waste — it was the cost of transition. You couldn't turn the old environment off until the new one proved itself. And once teams experienced how much faster they could move in the cloud, there was no appetite to go back.
AI adoption follows the same curve. Early on, organisations pay twice: existing workflows persist while AI is layered on top. Over time, some tasks disappear, some roles change shape, and some work simply gets done differently — but that only happens after teams have learned where AI genuinely adds leverage.
The mistake is expecting AI spend to stay flat during that learning phase. Just as with cloud, the period of fastest capability growth is also the period where costs appear least tidy. Only once usage stabilises — and the organisation deliberately decides what moves to AI-first workflows — does spend become predictable.
This is why AI costs often feel surprising. They're not ramping because something went wrong. They're ramping because the organisation is mid-transition, whether it has acknowledged that or not.
What you're actually buying with that spend
In one team I work with, analytics recently showed that roughly half of committed code was AI-generated.
That doesn't mean people were replaced. It means AI absorbed a large share of the mechanical work — scaffolding, refactoring, validation, documentation — that previously consumed significant time.
The practical effect showed up quickly. The team started attempting changes they had previously deferred: broader refactors spanning multiple services, more aggressive cleanup of legacy code, and faster iteration on fixes after incidents. None of that work was new — it had simply been perpetually postponed because it never quite fit into a sprint.
The reclaimed capacity created a real choice: raise quality and resilience without slowing delivery, or maintain quality while increasing throughput with the same headcount.
Either way, outcomes change materially. This is why comparing AI spend to SaaS licences misses the point. The correct comparison is team productivity and infrastructure, not cost per seat.
Why usage will continue to grow
Even if team size stays flat, AI usage will increase.
The next shift already underway is the move from single-prompt interactions to systems that iteratively attempt, test, and refine solutions without constant human involvement — not as chatbots, but as automated participants in existing workflows.
A common early example is CI/CD:
- A build or deployment fails
- The AI system reads compiler output, test failures, or pipeline logs
- It proposes one or more fixes — configuration changes, dependency updates, test corrections
- Applies those changes in a branch
- Re-runs the pipeline
- Repeats until the build passes or escalation criteria are met
This isn't speculative. Many teams are already running this pattern today, often with guardrails like capped retries or human approval before merge.
What previously took a human multiple cycles now happens in minutes — at the cost of additional tokens rather than additional hours. This isn't inefficiency. It's a deliberate trade-off: compute instead of human retry time.
Once teams experience this shift, they don't go back. Delegating retries, validation, and exploration to AI doesn't just save time — it changes how work feels. Problems become cheaper to explore, safer to attempt, and faster to resolve.
Engineers lean into these workflows because they materially improve quality and pace. Token usage increases not because of waste, but because each additional attempt has a positive return. Once that feedback loop exists, higher usage becomes a rational choice — not something teams willingly give up.
As more work is delegated this way — incident analysis, pipeline repair, refactoring, remediation — token consumption rises quietly, even with stable headcount.
The question isn't how to suppress that usage. It's how to supply it predictably and at the right cost.
The infrastructure behind the infrastructure
There's a reason every hyperscaler is racing to secure power capacity and build data centres. It's not speculative — it's demand they can already see.
This isn't just happening here. In the US, gas power projects tripled in 2025 — a third of them for AI data centres. Globally, the same pattern is playing out: teams discovering that problems which once required weeks of human effort can be explored in hours with enough compute. Research that was too expensive to attempt becomes routine. Experiments that never left the whiteboard get run in parallel.
This is what cheap, abundant reasoning enables. Not just automation of existing work, but work that was never economically viable before.
The bazillions of tokens flowing through those data centres aren't waste — they're the cost of exploration at scale. Every organisation working out where AI adds leverage is contributing to that demand. And as agentic systems become mainstream — retrying, validating, iterating without human involvement — token volumes will grow by orders of magnitude, not percentages.
The power stations and data centres aren't being built for today's usage. They're being built for what happens when this kind of capability becomes the default way work gets done.
A hybrid operating model
The answer isn't to throw away existing tools like Cursor, Claude, or ChatGPT Team. That $40-per-seat spend still makes sense — when it's used deliberately.
Frontier models are at their best for genuinely novel problems: unfamiliar domains, high-stakes reasoning, or one-off exploration. In practice, this tends to be a minority of daily usage — but it's valuable, and teams should keep it.
The mistake is letting all work flow through those same pricing models.
A more effective pattern:
- Keep your existing $40-per-seat tools for the ~20% of work that benefits most from frontier models
- Route the remaining ~80% of routine work to private capacity with predictable cost
- Access that capacity through familiar interfaces (OpenAI-compatible APIs), so teams don't have to change how they work
Most day-to-day AI usage is repetitive, internal, context-heavy, and predictable at scale. Roughly 80% can be handled by private or self-hosted models at fixed cost — with context windows in the hundreds of thousands of tokens already covering most real-world scenarios. The remaining 20% still benefits from frontier models.
This isn't about replacing anything. It's about not paying premium pricing for every token, all the time.
The mistake to avoid
The mistake isn't spending serious money on AI.
The mistake is budgeting for trial usage while planning for full adoption — and being surprised when costs stop behaving like SaaS and start behaving like infrastructure.
On Monday morning, the most useful questions aren't about how many licences you have:
- Which work genuinely needs premium models?
- Which work is already scaling quietly?
- Where does that capacity actually live today?
This is the problem space I work in: helping organisations adopt AI in a way that reflects how it's actually used — not how it's marketed.
Interested in private LLM hosting?
Let's talk about what your organisation actually needs.
Get in touch →